
Blog: Getting Beyond “Works Offline”
At Field, we try to build technology which is:
- As easy to access as possible and
- Built for users who are frequently — or mostly — offline.
It turns out there’s an amazing solution to that first constraint; a pretty ubiquitous delivery platform they call the World Wide Web. You might have heard of it. Unfortunately, it is not super good at 2) - working offline. At least, until recently.
“Offlineness” is a condition which affects enough people that we have been steadily accumulating ways to deliver all our lovely web content over unlovely connections for quite a while now, and in 2015 some smart people at google put a name on what you get when you put a bunch of those technologies together; a Progressive Web App, or PWA.
You’ve probably used a PWA by now; think Instagram, Google Maps, Uber, Pinterest or Forbes. One of the key features of a PWA is that it is offline capable, and as awareness grows that users worldwide are in fact not permanently jacked into the cloud via ubiquitous high speed connections, “offline first” as a design, engineering, and marketing principle has been gaining traction; apps proudly advertise offline capability, and quick-start guides to building offline first apps abound.
The thing is, in practice, “offline capable” is not a binary property, there is a lot more to providing functionality to occasionally connected users than throwing a service worker and some local storage at an app, and if you’re building or buying a system for offline or occasionally connected contexts, you probably need a more nuanced way of talking about this. At any rate, we did.
First steps offline: store-and-forward
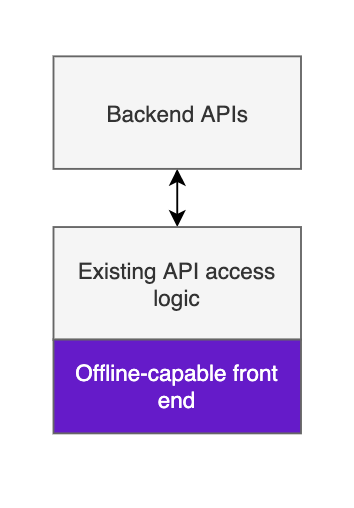
Like some sort of Devonian lungfish taking its first tiny breaths of dry air, basic PWAs utilize service workers and web storage to cache assets and data for their limited expeditions offline.
This means someone can load your app, enter some data, and save it to be sent later when they’re back online. Think writing an email offline and putting it in the outbox, or sending a message in a chat app.
What is exciting about this capability is that it is relatively high value for relatively low effort. A legacy client-server application can immediately become offline-tolerant by simply upgrading the front-end with:
A cache — using web storage to save the contents of forms, and service worker to cache assets offline. A queue — to detect the network state of your app and, when the coast is clear, fire off the back end requests that would have been sent had you been online all along.
Only some relatively straightforward front-end work is required (great for legacy systems), users can enter data and browse around with nary a mast or wifi signal in sight.
This is very cool. But.
Simply stringing out a data submission process until connection returns is not what most users will have in mind when they think “offline capable”. Our proto-offline PWA can spend time out of the water but must return regularly to the primordial backend — in this case, every time we want to do something useful with our data.
The problem is, users usually enter data into a system in order to see something happen to that data; immediately, if possible.
Taking your logic offline
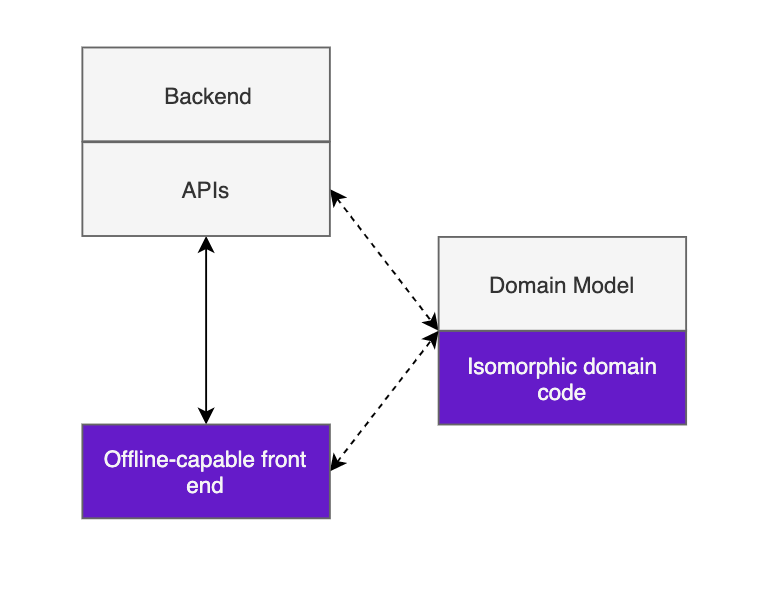 A pharmacist who is entering an inventory update offline will usually want to see how the new inventory levels compare to their plan, and perhaps what the new data say about a trend in consumption — immediately.
A pharmacist who is entering an inventory update offline will usually want to see how the new inventory levels compare to their plan, and perhaps what the new data say about a trend in consumption — immediately.
Achieving this offline is a far cry from our original “outbox” style behaviour, as now the application needs to be able to make decisions without access to an online backend.
The first step to achieving this is putting the relevant business logic for inventory levels and plan comparison into the client so it can be run offline, on local data. Javascript is the language of the front end so this means (re?)writing domain logic in js, and if your app only ever needs to provide users with local results based on local data, you can stop there.
In almost any information system however you also need the ability to execute the same logic on the universe of data available online — say, to calculate an aggregate of inventory levels compared with plans across all clients. We achieve this with:
Isomorphic domain code — Traditionally, you might solve this problem with a common SDK, included in server-side components and native apps. Although much can be said about javascript’s fit for large applications, one significant upside is that, properly modularised, we can run the same code in client-side apps and backend components (in our case, serverless functions) alike, maintaining a consistent dev environment and shedding a bunch of build overhead and language impedance.
Moving legacy business logic into client code without creating duplication and inconsistencies is a challenge for existing client-server apps, and one of the reasons add-on offline clients for existing client-server apps are often so limited.
A fully amphibious PWA: online-offline transparency
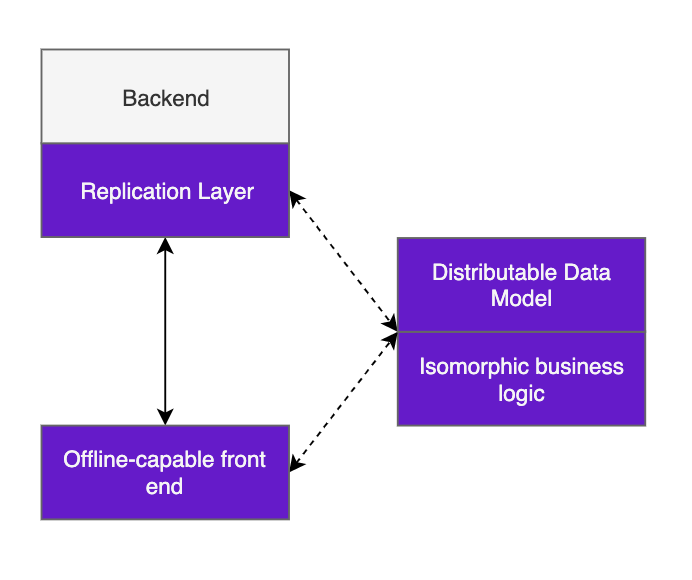 Achieving equivalent logical functionality on- and offline is probably as far as many offline-capable apps need to go to be useful. Many domains however, supply chain included, are inherently networked, in that the value of the application comes from combining data from multiple users.
Achieving equivalent logical functionality on- and offline is probably as far as many offline-capable apps need to go to be useful. Many domains however, supply chain included, are inherently networked, in that the value of the application comes from combining data from multiple users.
A classic example in our world is a shipment between two stores:
- Store A records what they’ve sent to store B (offline)
- Store B records what they’ve received (offline)
- Both find connection again and upload their records, in some random order as they find a working mast somewhere
- Finally, both need to see — and relate — each others’ data, to reconcile any potential discrepancies in their versions of events
If we had never tried to take any data offline this would be relatively easy, as all clients would simply utilise the shared truth of a single online backend.
Allowing multiple users to enter shared data offline however — and have it make sense when they eventually connect again — is a challenge that neither of our two previous models address, and gets at the heart of the differences between off- and on-line first systems: challenges of concurrency that are difficult to abstract or ignore.
Concurrency issues have always been with us — they are why we have database transactions and locks and mutexes. Most of these solutions effectively rely on telling everyone to get in line and apply their updates in order. When our users can’t necessarily talk to each other, and can’t necessarily wait for each other, we need to think harder.
Distributable data models — Fundamentally, allowing distributed updates to shared data requires modelling your data to deal with the possibility of conflicts.
Imagine we were to store our shipment above as a single database row with a single status column. Our sender and receiver mark this shipment sent and received respectively, both offline. If our sender then comes online and tries to send her status=sent update after our receiver has sent her status=received update, we run into problems.
There are many ways to solve this; at Field we employ judicious use of event sourcing for records which we can decompose into updates, and vector clocks for records which can’t (or don’t want to) — but in either case we’re baking considerations for offline updates into our data model from the start.
In our experience data modelling for distributed updates is the biggest differentiator of fully offline capable networked applications, and though solutions exist, they almost universally add complexity to the system which must be planned for.
Shades of offline-ness
As is hopefully pretty apparent by now, there are no turnkey solutions to making a rich, connected offline application. As is true in so much of engineering, complexity is conserved and the question is less how to avoid it as much as where it is best dealt with.
It is therefore a good idea to consider up front how much “offline” you really need. Throughout our time working across private and public sector projects we’ve begun describing the options in the following terms, to help stakeholders get on the same page at the start of a project.
Offline architecture checklist
As you can see, depending on the situation, the most appropriate solution might not always be a PWA, and the decision point is almost never simply Offline: Y/N?